|
Zhiwei Zheng I am currently a second-year Ph.D student at University of Pennsylvania, focusing on multi-modality learning and generation, advised by Prof. Mingmin Zhao. Before that, I obtained my Master's degree in EECS and Bachelor's degree in Automation from UC Berkeley and Huazhong University of Science and Technology, respectively. I also interned at Shanghai AI Lab, working on autonomous driving. |

|
Research InterestMy research focuses on multi-modal learning, integrating point clouds, images, and wireless signals to advance robotic perception in areas like autonomous driving and quadruped robotics. In addition, I explore scene generation, scene-aware human motion and interactions with other agents, and signal simulation for diverse sensing modalities, with a broader goal of bridging the sim-to-real gap. |
Selected Paper |
|
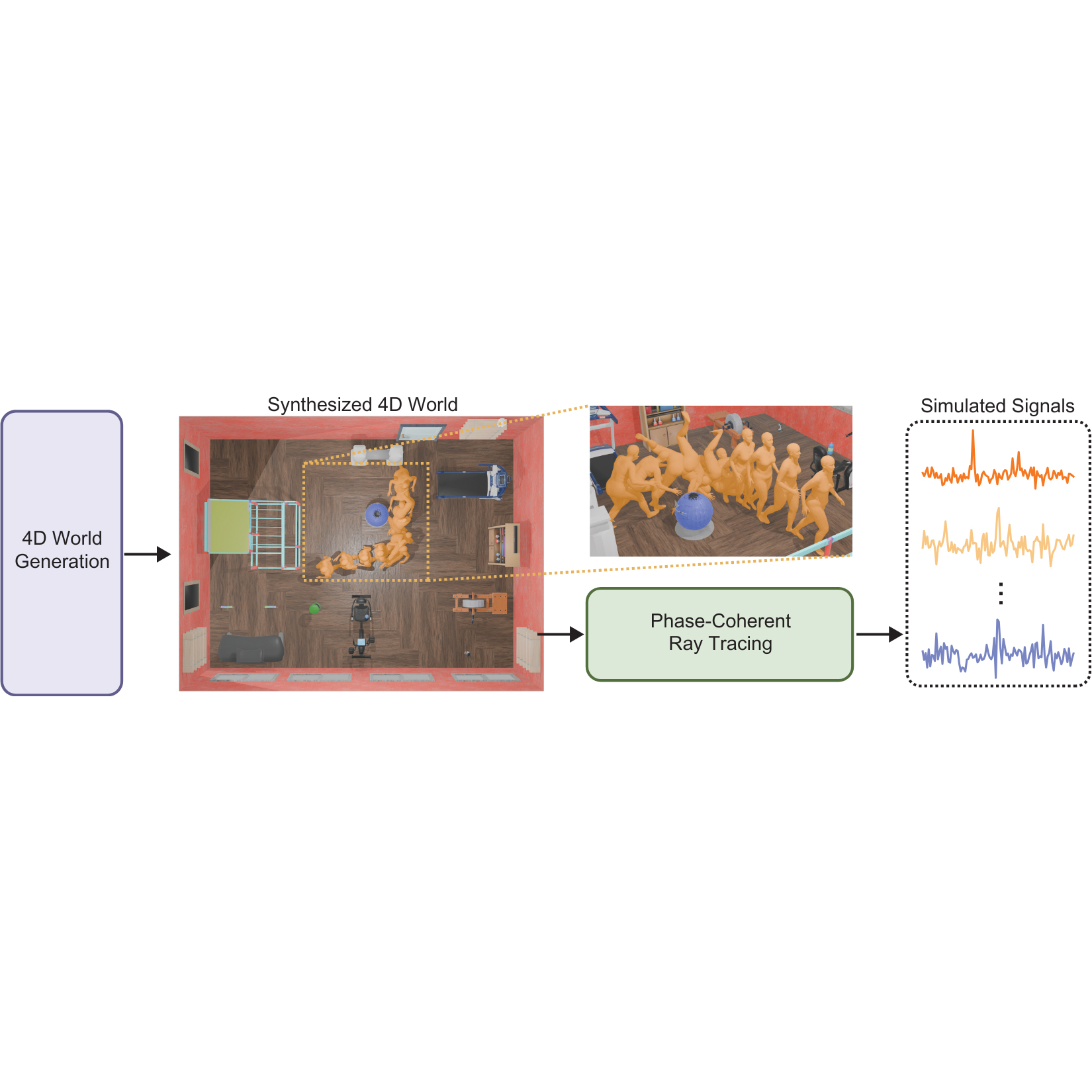
Scalable RF Simulation in Generative 4D Worlds
Zhiwei Zheng, Dongyin Hu, Mingmin Zhao arXiv[Under Review], Webpage. We leverage LLM for diverse scene generation with corresponding human motion, and propose a phase-coherent ray tracing for RF signal simulation in a scalable way. It enables performance gain in both data-limited and data-adequate scenarios. |

|
Next-Scale Autoregressive Models for Text-to-Motion Generation
Zhiwei Zheng, Shibo Jin, Lingjie Liu, Mingmin Zhao CVPR 2026, Webpage. We present MoScale, an autoregressive framework for hierarchical motion generation that integrates cross-scale hierarchical refinement and in-scale temporal refinement. Experiments demonstrate that MoScale achieves new SOTA performance and generalizes zero-shot to various motion generation and editing tasks. |
|
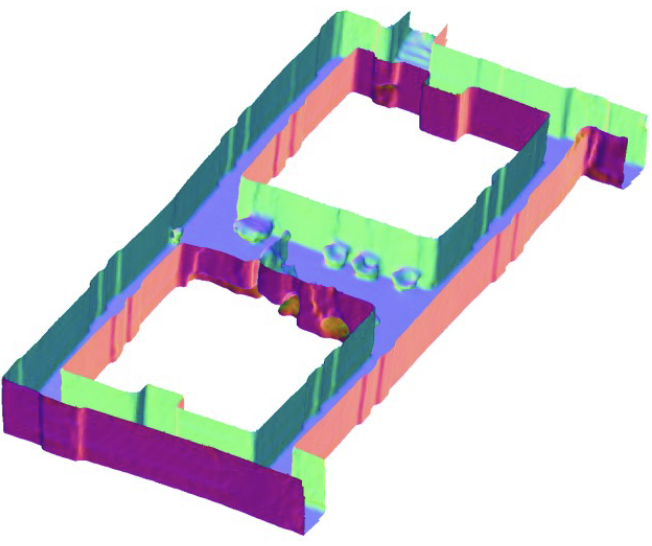
RF-Based 3D SLAM Rivaling Vision Approaches
Haowen Lai*, Zhiwei Zheng*, Mingmin Zhao MobiCom 2025 (Best Artifact Award), Webpage. We propose an uncertainty quantification specifically designed for wireless signals and probabilistic learning for occupancy field training to enable high-resolution SLAM relying on RF signals only. |
|
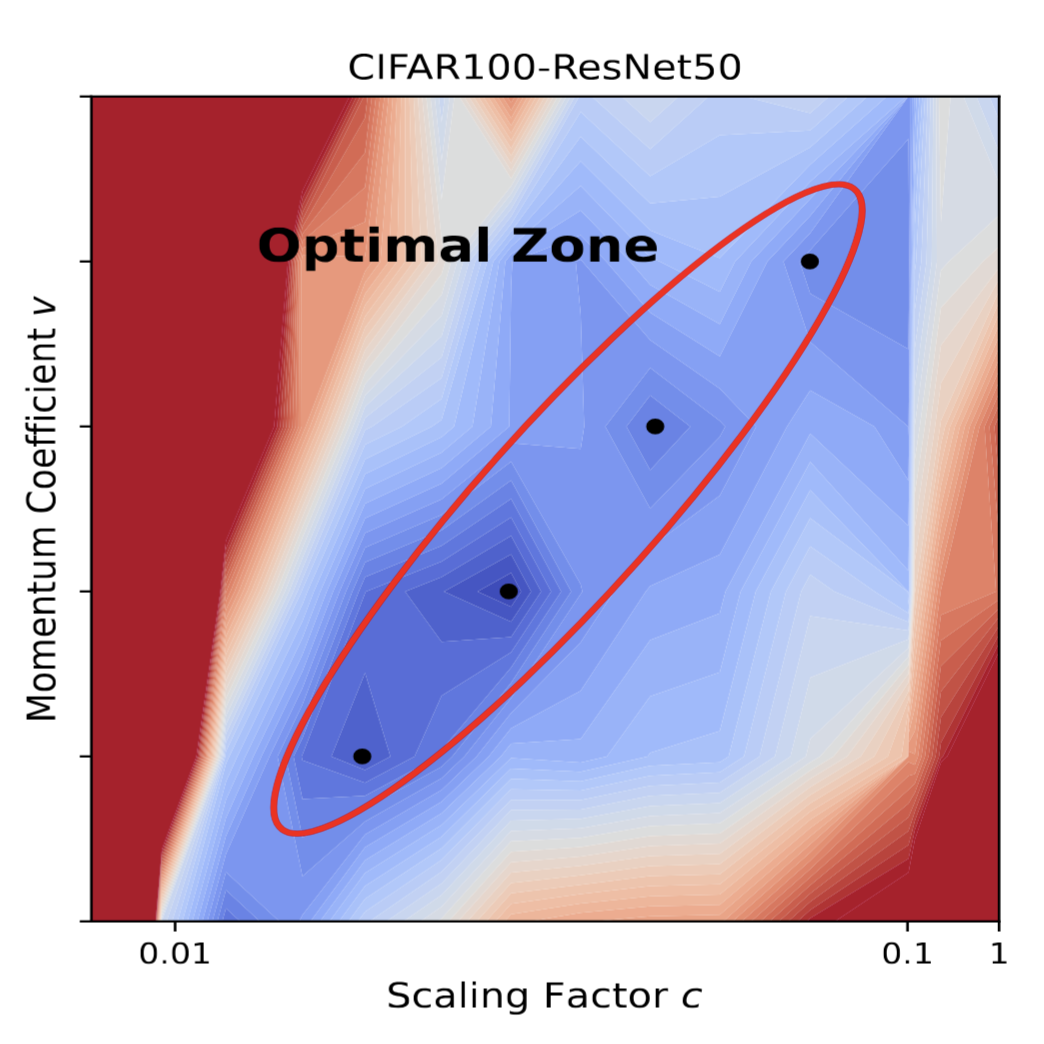
On the Performance Analysis of Momentum Method: A Frequency Domain Perspective
Xianliang Li*, Jun Luo*, Zhiwei Zheng*, Hanxiao Wang, Li Luo, Lingkun Wen, Linlong Wu, Sheng Xu ICLR 2025. We present a frequency domain analysis framework that interprets the momentum method as a time-variant filter for gradients and propose a heuristic optimizer. |

|
Acoustic Volume Rendering for Neural Impulse Response Fields
Zitong Lan, Chenhao Zheng, Zhiwei Zheng, Mingmin Zhao NeurIPS 2024 (Spotlight), Webpage. We propose acoustic volume rendering in the frequency domain to construct neural impulse response fields. |
|
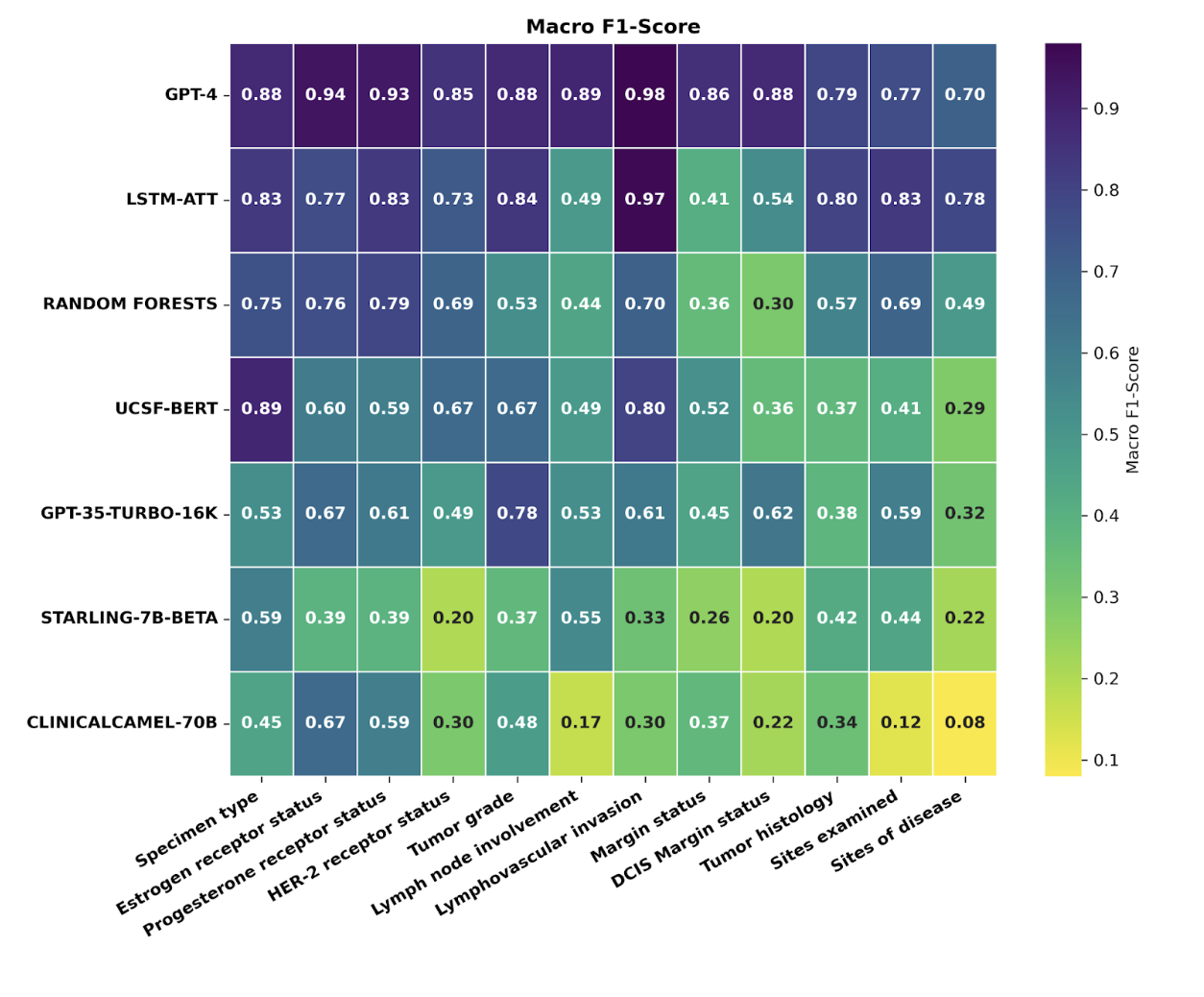
A comparative study of large language model-based zero-shot inference and task-specific supervised classification of breast cancer pathology reports
Madhumita Sushil*, Travis Zack*, Divneet Mandair*, Zhiwei Zheng, Ahmed Wali, Yan-Ning Yu, Yuwei Quan, Dmytro Lituiev, Atul J Butte JAMIA 2024. We explore whether LLMs could reduce the need for large-scale annotations for clinical reports. |
|
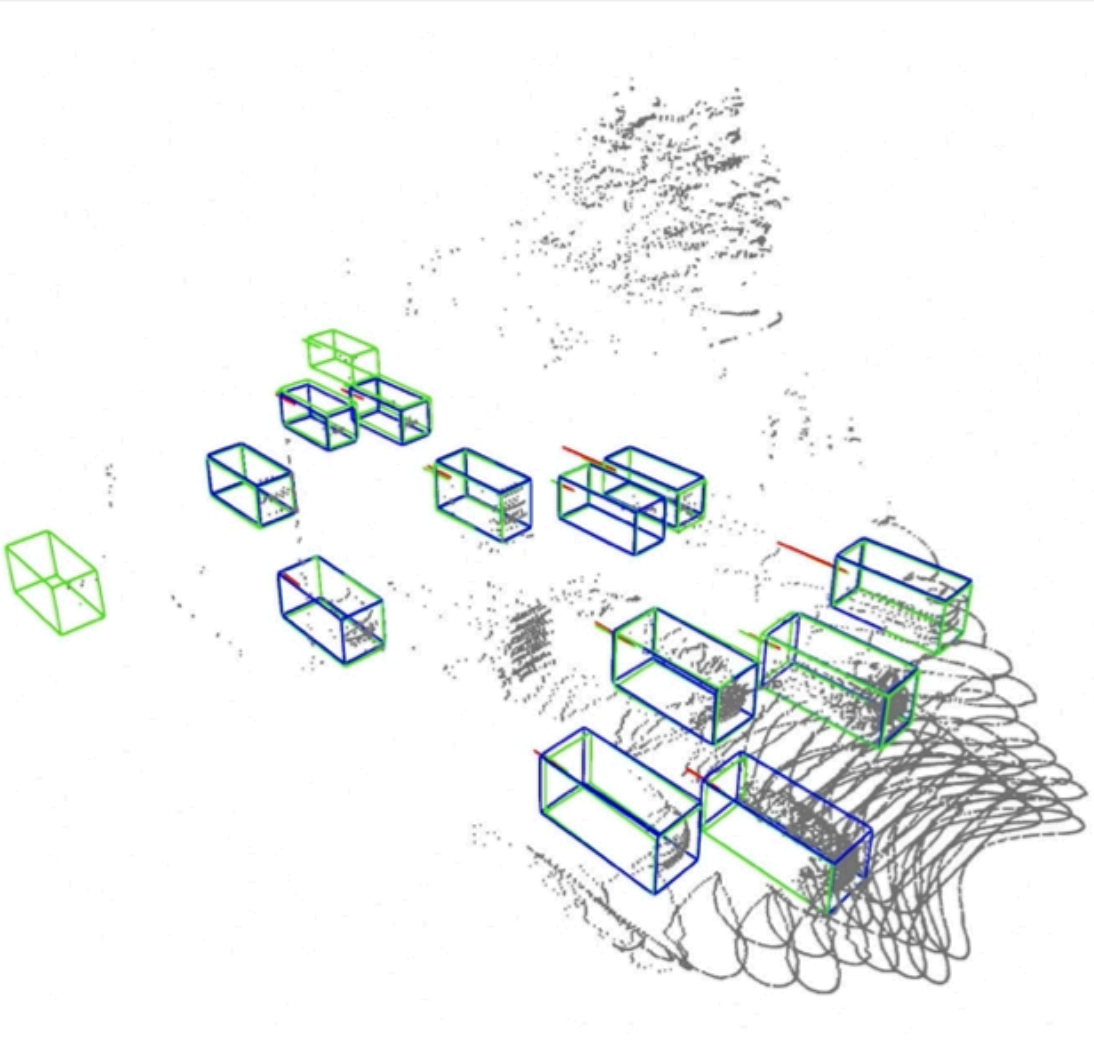
VeloVox: A Low-cost and Accurate 4D Object Detector with Single-frame Point Cloud of Livox LiDAR
Tao Ma*, Zhiwei Zheng*, Hongbin Zhou, Xinyu Cai, Xuemeng Yang, Yikang Li, Botian Shi, Hongsheng Li ICRA 2024. We achieve velocity estimation with only one frame of point clouds. |
Miscellaneous
|


|
Design and source code from Jonathon Barron's website. |