Autoregressive (AR) models offer stable and efficient training, but standard next-token prediction is not well aligned with the temporal structure required for text-conditioned motion generation. We introduce MoScale, a next-scale AR framework that generates motion hierarchically from coarse to fine temporal resolutions. By providing global semantics at the coarsest scale and refining them progressively, MoScale establishes a causal hierarchy better suited for long-range motion structure. To improve robustness under limited text–motion data, we further incorporate cross-scale hierarchical refinement for improving coarse-scale predictions and in-scale temporal refinement for selective bidirectional re-prediction. MoScale achieves state-of-the-art text-to-motion performance with high training efficiency, scales effectively with model size, and generalizes zero-shot to diverse motion generation and editing tasks.
Below, we present qualitative results for text-to-motion generation, including comparisons with prior methods, as well as zero-shot conditional and unconditional motion inpainting, outpainting, editing, and continuous motion generation.
Note: We follow the standard visualization pipeline, using the SMPL fitting pipeline in MLD [1], as adopted in other text-to-motion works. This pipeline is known to sometimes produce abrupt changes in human shape during SMPL fitting, which often come with discontinuous poses. These artifacts are caused by the fitting stage rather than motion generation and can also be observed when visualizing the real motions. We can provide the original skeleton visualizations if needed.
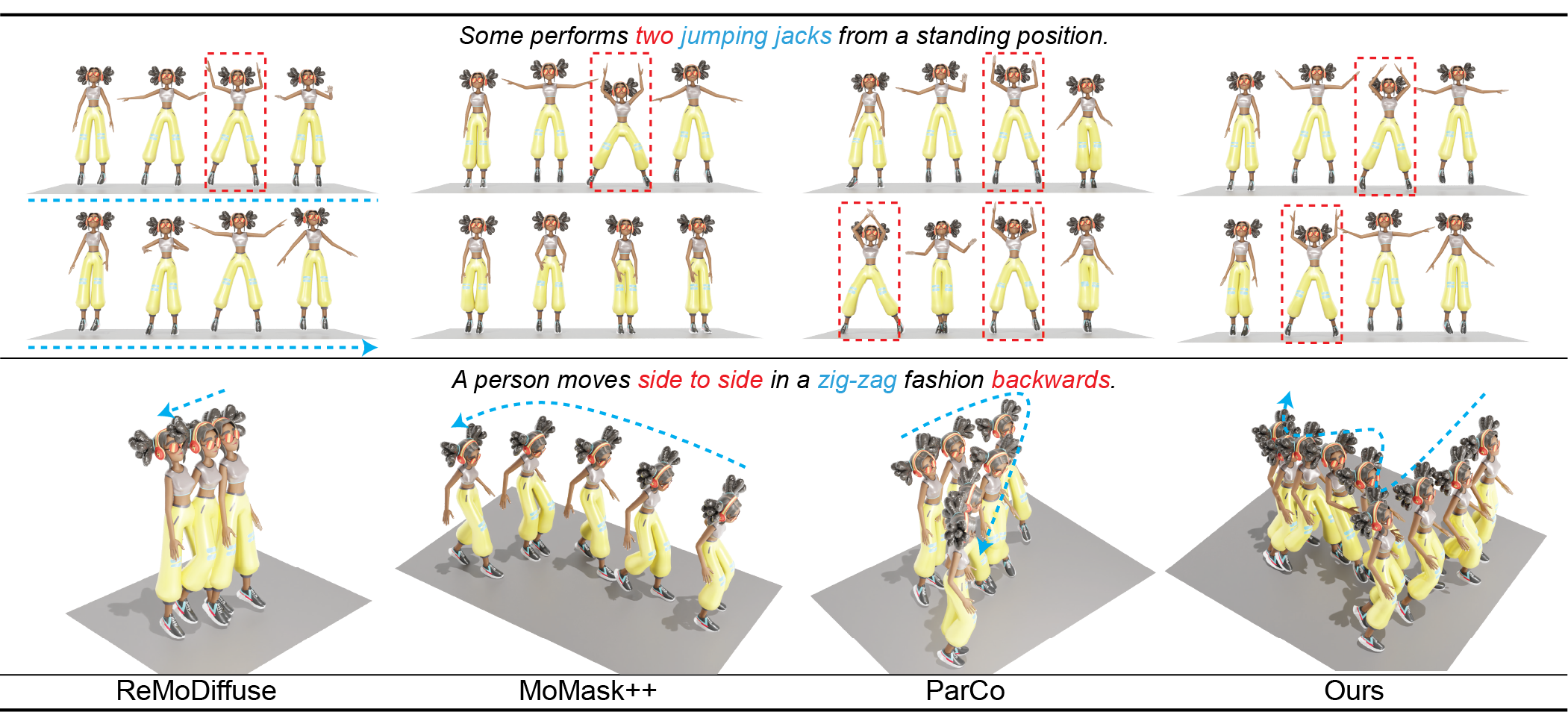
We provide qualitative results for text-to-motion generation, including comparisons with MoMask++, ParCo and ReMoDiffuse. For ReMoDiffuse, we do not apply the post-process temporal filtering adopted in the original codebase for a fair comparison.
Ours (Next-Scale AR)
MoMask++ (MaskedTrans)
ParCo (Next-Token AR)
ReMoDiffuse (Diffusion)
"The person stands up while holding their right hand above their head."
"Running forward taking a right turn then running to the left."
"Person stands still with both arms raised at shoulder height."
"The man walked forward, spun right on one foot and walked back to his original position."
"A man lifts his hands up in front of his face and turns to his right, and then his left, and puts his hands back down."
"A man supports himself with his right hand, carefully going down to his knees."
In the above examples, our method demonstrates clear improvements in text alignment, particularly for detailed descriptions involving directions, motion sequences, adjectives, and expressive language, while maintaining high motion fidelity.
We provide qualitative results for zero-shot text-conditioned motion inpainting, outpainting, and editing, including comparisons with MoMask and BAMM. We highlight the painted/edited regions with blue colors. To better compare with the original motion in the unedited regions, we also render the original motion in blue at the corresponding timestamps where edits/paintings are applied. We use orange to represent unedited regions.
Note: We follow prior work and represent the motion with a sequence of root (pelvis) velocities, while the remaining joints are encoded as their 3D positions in the root’s local coordinate system. Under this representation, preserving the unedited regions means keeping the root velocity sequence and local joint positions identical in those frames. As a result, the character exhibits the same motion pattern (how it moves and poses over time) in those segments, even though its absolute global positions may change if earlier parts of the motion are changed.
Original Motion
Ours
BAMM
MoMask
"Inpainting: The figure looks like it is picking something up and raising it above its head twice."
"Outpainting: Lowering arms from shoulder height to waist then bending arms 90 degrees forward and rotating circular."
"Editing: A person walks forward and then waves the hand to the end."
"Editing: A person keeps running forward. (from 40 frames to 176 frames)"
Our method again shows better alignment with the text instructions, and our editing can also generalize well to the change in motion length (e.g., the last example). Moreover, compared to other methods, MoScale better preserves the unedited regions of the original motion, producing smoother and more natural transitions between the edited and unedited segments.
We show that MoScale can also perform zero-shot unconditional motion inpainting and outpainting.
Original Motion
Generated Instance 1
Generated Instance 2
Generated Instance 3
"Unconditional Inpainting"
"Unconditional Outpainting"
Our method is able to generate diverse and plausible motion completions for both inpainting and outpainting tasks, while maintaining coherence with the existing motion segments.
"A person stands up from a chair and walks forward. → The person runs to his left. → The person changes to run to the right. → The person suddenly stops."
[1] Chen, Xin, Biao Jiang, Wen Liu, Zilong Huang, Bin Fu, Tao Chen, and Gang Yu. "Executing your commands via motion diffusion in latent space." In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 18000–18010. 2023.
@InProceedings{Zheng_2026_moscale,
author = {Zheng, Zhiwei and Jin, Shibo and Liu, Lingjie and Zhao, Mingmin},
title = {Next-Scale Autoregressive Models for Text-to-Motion Generation},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2026},
pages = {16376-16386}
}